redis集群
redis集群是由多个节点实例组成的网状拓扑结构,每一个节点有两个对外服务的端口,一个是面向普通客户端的正常服务(默认端口是6379),另一个则是用于集群内节点交流的服务(默认端口是6379+10000),主要包括增加节点、删除节点、分配哈希槽点、迁移槽点、故障修复等功能。集群的实现和哨兵的实现有相同的地方,也有不一样的地方。相同点是二者都支持主从模式,并且在master挂掉之后,能够自动发现并修复。不一样的地方是哨兵模式下的故障修复是从哨兵中选出一个leader,参与投票的也是哨兵节点,然后由leader哨兵主导完成整个修复过程。在集群模式下,则不存在哨兵这样的领导层角色节点,故障修复过程则是由挂掉master下的slave节点发起,其余master参与投票来选出一个slave来主导修复过程。
redis集群的实现引入了哈希槽的概念,将整个集群分为16384个槽点,集群中每个节点负责其中的一部分。通过对命令中key进行运算,结果对总的槽点取余来决定应该访问哪个槽点。当集群稳定后,集群中每个槽点都会有一份完整的槽点路由表,记录每个槽点应该去哪个节点。
集群组成
节点
一个节点有以下信息,是其他节点都知道的:
- IP、端口、集群端口
- 标识位,比如是master、是slave、客观下线、主观下线、握手中
- 节点使用的槽点情况
- 最近一次发送ping的时间
- 最近一次收到ping的时间
- slave节点的数量
- 主节点的信息
在使用redis-cli创建集群的时候,会选取第一个master节点作为标杆,其余的master节点向第一个节点发送MEET消息,消息内会带上自身的信息,ip、端口、名称等信息。节点接收到MEET信息后,会把该节点作为集群中的一部分记录下来,然后在定时任务中,对自己已知的节点发送PING命令来进行心跳检测和交流,收到PING命令的节点则会回复PONG命令。在MEET、PING、PONG命令中,都会附带当前节点的部分已知节点信息,收到命令的一方,则会把该节点添加到自己的已知节点中。在经过多次交流后,每两个节点都会知道彼此的全部已知节点信息。
集群是由多个master主节点组成,为了提升集群的高可用性,解决某个master挂掉之后,部分槽点变得不可用的情况,通常会为每个master配置一个或多个slave从节点。当master挂掉之后,从其slave节点中提取一个成为新的master。
集群中节点都是直接连接的,不存在向哨兵那样的管理节点。在由N个节点组成的集群中,每个节点都有N-1个连接,从结构上来看,像是一个图结构。节点之间交流的的时候,会带上自身的信息和自己的槽点路由表。因此在构建集群的时候,我们只需要把所有节点连接成一个树就好了,在经过一段时间的交流后,最终形成一个完整的图。比如A知道B,B知道C,B跟A交流的时候,会告诉A自己知道C,然后A知道了C,同样的B跟C交流的时候,C也会知道A。下图所示的就是我们在构建集群开始的拓扑,和集群稳定后的拓扑。
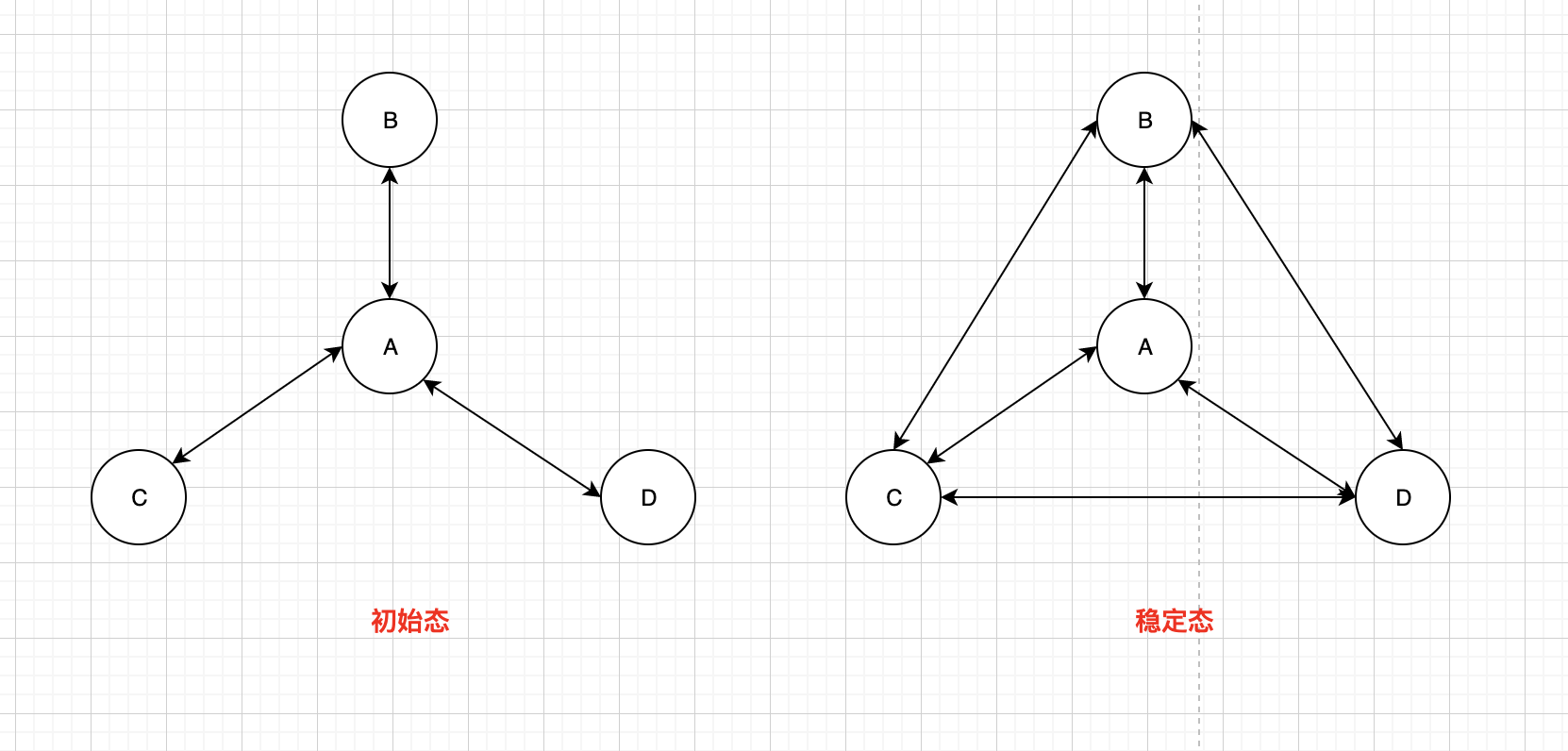
master节点的数量最低为3,因为当master挂掉之后,一个slave节点能够成为新的master,是需要获得一半以上master票数的支持的。一个或两个master节点组成的集群,其一半以上的数量就是总的master节点数量,在某个master挂掉后,是永远都不满足的这个条件的。而三个节点的话,一半以上的数量最低是2个,是能够满足的。
创建集群
创建集群分为两步,第一步是节点通过MEET命令构建成一个连通图,第二步是节点通过gossip协议交流,完善各自的拓扑结构。在第一步中,是需要一个额外的工具来完成的,可以是纯手工操作、redis-cli cluster命令或者redis-trib.rb脚本。
握手过程
- 脚本向节点A发送
MEET命令,要求节点A去会见节点B,此时A创建一个node,填充上ip、port、cport,标记CLUSTER_NODE_HANDSHAKE & CLUSTER_NODE_MEETnode->link为空,node->name是随机生成 - 节点A在定时任务里,发现此node->link为空,创建根据node->ip,node->cport创建连接,指定连接的读响应处理为
clusterReadHandler,此时link->node=node;node->link=link;,link和node完成关联 - 节点B
clusterAcceptHandler收到链接请求,创建一个link,link->node为空,指定连接的读响应处理同样为clusterReadHandler - 节点A发送
MEET消息,消息里有节点A的名字 - 节点B接受到完整信息后,调用
clusterProcessPacket处理MEET消息。创建一个node填充ip、port、cport,并标记CLUSTER_NODE_HANDSHAKE,处理gossip信息并回复PONG - 节点A收到
PONG回复,因为node还在握手阶段,所以会根据PONG回复里的节点B名字来更新node->name。node结束握手阶段,给node打上master或者slave标签 - 节点B在定时任务中,发现node->link为空,创建跟节点A的link,此时
link->node=node;node->link=link;,link和node完成关联连接后续处理为clusterReadHandler,发送PING消息给A - 节点A回复
PONG - 节点B收到完成消息,调用
clusterProcessPacket处理PONG消息,更新node->name。节点B的node握手结束,打上master或者slave标签
整个过程如下图所示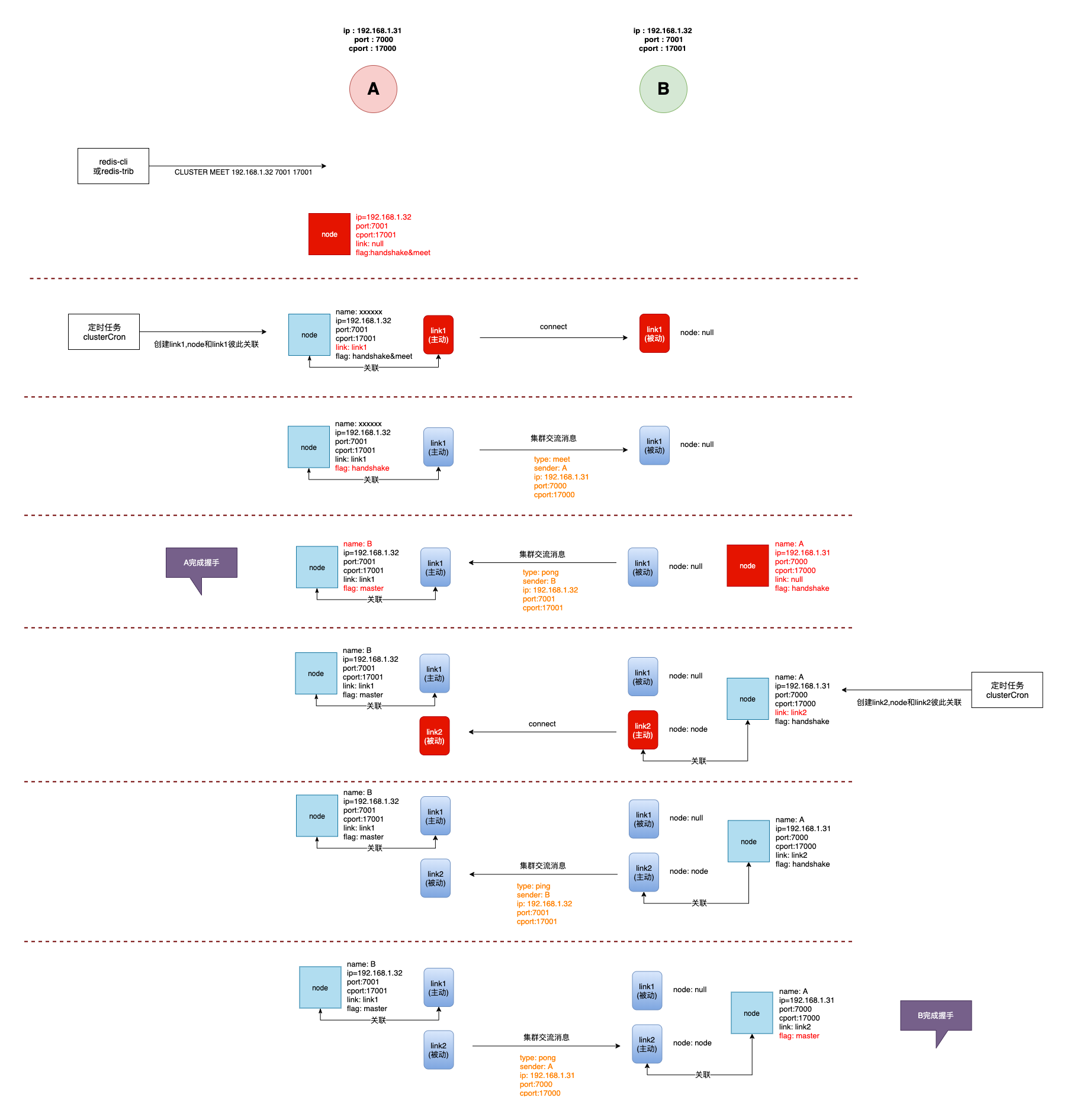
最终的,节点A跟节点B各有两个link,一个是主动发起的link,和node互相绑定;一个是被动连接的link,根据消息里的sender查找本地对应的node。这两个连接也有特殊的用途,当一个节点的ip、port、cport发生变化时,我们可以通过主动的link来告知其他节点,我们的连接信息发生变化了。比如节点A和B互相建立的连接,节点A在某一刻ip发生变化了,在后续发给节点B的PING消息中,会带上自己的最新ip。节点B在收到消息后,发现消息中节点A自报的ip和自己已知nodeA中的ip信息不一致,这时就会删除nodeA中的link,也就是主动的link,并更新nodeA的ip。在下一次定时任务时,会使用更新后的信息,建立跟节点A的连接。
因此在clusterProcessPacket中看到if (link->node),表示是我们发起的主动连接,if (sender)则表示消息里的name对应的节点是我们已知的节点。
槽点(哈希槽)
redis集群的实现没有使用一致性哈希,而是采用了槽点的概念。整个集群共有16384个槽点,每个master节点分别负责其中的一部分,每个节点都有一份完整的槽点路由表,记录着每个槽点对应的节点的信息。这样客户端只需要连接集群中任意一个节点,该节点就能正确告知客户端应该去哪个真正的节点进行操作。
槽点哈希
当我们在集群中执行命令的时候,服务端会把键值进行CRC16计算,然后对总槽点数进行取余,来决定该命令应该落到哪个槽点,然后根据槽点路由表,找到集群中对应的节点来处理命令。
针对键值的计算,有以下规则:
- 如果键值里包含”{}”, 且第一对”{}”中间的内容不为空,那么只有第一个”{}”之间的内容会参与
CRC16计算。eg: key ={user}100{qaq}, 参与计算的数据为user - 如果键值里包含”{}”, 且第一对”{}”中间的内容为空,整个键值都会参与计算。eg: key =
{}user100,参与计算的数据为{}user100 - 如果键值里不包含”{}”,整个键值都会参与计算。eg : key =
user100,参与计算的数据为user100
总的来说就是,当且仅当键值中第一对”{}”中间不为空时,才会使用第一对”{}”之间的内容进行计算,否则会使用整个键值的内容。
如果命令涉及到多个key,当且仅当所有key都分布在同一个槽点才能正常响应。比如
mget,当key分布在不同槽点的话,会返回一个错误(error) CROSSSLOT Keys in request don't hash to the same slot。我们可以利用上面的规则使用”{}”规则,强制把多个key分布在同一个节点上,这样就能正常响应多key请求了。
槽点迁移
由于某些原因(人为故意的、碎片整理),我们需要对槽点进行节点间的迁移。槽点在迁移的过程中有两个状态MIGRATING和IMPORTING,比如我们要把槽点1从节点A迁移到节点B上。需要执行以下两步:
- 向目标节点B发送命令 :
CLUSTER SETSLOT 1 IMPORTING A,表示从A节点迁移槽点1 - 向源节点A发送命令 :
CLUSTER SETSLOT 1 MIGRATING B, 表示把槽点1迁移到B
故障修复
在一个良好的redis集群拓扑中,至少有3个master节点组成,每个master至少有一个salve节点。在某个master挂掉之后,其下面的salve节点检测到master不可用,会将该master标记成PFAIL主观下线状态。在后续跟其他节点交流的过程中,统计其他节点是否也检测到该master不可用。当标记master不可用的节点数量达到集群中总节点数量一半以上时,slave将其标记成FAIL客观下线。然后会发起一个投票,希望自己能够成为故障修复的执行者,请求其他master投自己一票。当一段时间内,有超过一半以上的master同意了,那么就可以成功当选,否则会在下一次再尝试发起。
成功选举后,slave会进行以下操作:
- 把自己变成master,去掉salve标记,打上master标记,把自己从之前master节点下的salve列表中删除,更新自己的纪元
- 删除掉主从同步中master标记,断开跟master以及自己下面所有salve的连接
- 把之前master负责的槽点划分到自己下面
- 广播告知其他节点,更新拓扑结构
- 其余节点在收到slave的后续交流消息时,发现旧的master负责的槽点,现在被新的master宣布说他负责,则更新自己的拓扑结构。如果是旧master下的slave节点收到消息的话,则会更改自己的master,成为新master的slave
这个过程也可以手动执行,当我们想强制提升一个slave为master的时候
客户端查询
连接单点的实例时,我们通常用redis-cli -h xxxx -p xxxx去连接,针对于集群的话,我们需要加上-c参数,在该命令下,如果服务端返回ASK,MOVED命令的话,能够自动切换到对应的节点进行查询,否则的话,会看到一个异常报错。
源码分析
数据结构
1 |
|
初始化
clusterLoadConfig
从文件中加载集群配置
1 | int clusterLoadConfig(char *filename) { |
clusterSaveConfig
保存集群配置
1 | int clusterSaveConfig(int do_fsync) { |
clusterSaveConfigOrDie
保存配置文件,失败的话退出
1 | void clusterSaveConfigOrDie(int do_fsync) { |
clusterLockConfig
对配置文件进行加锁,防止多个实例使用同一个集群配置文件,使用文件锁
1 | int clusterLockConfig(char *filename) { |
clusterUpdateMyselfFlags
更新自身的标志
1 | void clusterUpdateMyselfFlags(void) { |
clusterInit
集群初始化
1 | void clusterInit(void) { |
clusterReset
集群重置
1 | void clusterReset(int hard) { |
节点交流连接
createClusterLink
创建连接
1 | clusterLink *createClusterLink(clusterNode *node) { |
freeClusterLink
释放连接
1 | void freeClusterLink(clusterLink *link) { |
clusterAcceptHandler
客户端初次连接处理
1 |
|
键值哈希处理
keyHashSlot
key到槽点的映射,当且仅当key中第一对{}中间是非空的, 才会使用{}中间的内容做计算,否则使用整个key
1 | unsigned int keyHashSlot(char *key, int keylen) { |
节点相关
createClusterNode
创建节点
1 | clusterNode *createClusterNode(char *nodename, int flags) { |
clusterNodeAddFailureReport
处理新来的汇报某节点挂掉
1 | int clusterNodeAddFailureReport(clusterNode *failing, clusterNode *sender) { |
clusterNodeCleanupFailureReports
清理汇报时间在很久之前的汇报
1 | void clusterNodeCleanupFailureReports(clusterNode *node) { |
clusterNodeDelFailureReport
删除某个来源对某个节点的汇报
1 | int clusterNodeDelFailureReport(clusterNode *node, clusterNode *sender) { |
clusterNodeFailureReportsCount
获取节点被汇报的有效数量
1 | int clusterNodeFailureReportsCount(clusterNode *node) { |
clusterNodeRemoveSlave
删除master下的某个slave
1 | int clusterNodeRemoveSlave(clusterNode *master, clusterNode *slave) { |
clusterNodeAddSlave
master增加slave
1 | int clusterNodeAddSlave(clusterNode *master, clusterNode *slave) { |
clusterCountNonFailingSlaves
统计master状态良好的slave数量
1 | int clusterCountNonFailingSlaves(clusterNode *n) { |
freeClusterNode
释放节点
1 | void freeClusterNode(clusterNode *n) { |
clusterAddNode
增加节点
1 | int clusterAddNode(clusterNode *node) { |
clusterDelNode
删除节点
1 | void clusterDelNode(clusterNode *delnode) { |
clusterLookupNode
根据名称查找节点
1 | clusterNode *clusterLookupNode(const char *name) { |
clusterRenameNode
节点重命名
1 | void clusterRenameNode(clusterNode *node, char *newname) { |
配置纪元
clusterGetMaxEpoch
获取所有节点中最大的配置纪元
1 | uint64_t clusterGetMaxEpoch(void) { |
clusterBumpConfigEpochWithoutConsensus
从所有节点中获取最大的纪元,来更新自己的配置纪元,一步到位
1 | int clusterBumpConfigEpochWithoutConsensus(void) { |
clusterHandleConfigEpochCollision
根据某个节点的配置纪元,来更新自己的配置纪元,自增
1 | void clusterHandleConfigEpochCollision(clusterNode *sender) { |
后备列表
当我们删除一个节点的时候,为了控制在一段时间内,忽略掉该节点的重新加入,引入了一个后背列表的概念。就是当节点删除后,会把节点放在后背列表中,有新节点要加入的时候,我们会先看一下是否在后备列表中,在的话就忽略了。节点存在于这个列表中的时效是1分钟。
clusterBlacklistCleanup
清理列表中过期的节点
1 |
|
clusterBlacklistAddNode
向列表中增加节点,如果节点已经存在,则更新过期时间
1 | void clusterBlacklistAddNode(clusterNode *node) { |
clusterBlacklistExists
查找节点
1 | int clusterBlacklistExists(char *nodeid) { |
集群消息
markNodeAsFailingIfNeeded
标记节点故障
1 | void markNodeAsFailingIfNeeded(clusterNode *node) { |
clearNodeFailureIfNeeded
清除故障标记
1 | void clearNodeFailureIfNeeded(clusterNode *node) { |
clusterHandshakeInProgress
是否有对应的ip&port&cport在握手中
1 | int clusterHandshakeInProgress(char *ip, int port, int cport) { |
clusterStartHandshake
开始握手
1 | int clusterStartHandshake(char *ip, int port, int cport) { |
clusterProcessGossipSection
处理ping/pong/meet消息中的gossip信息
1 | void clusterProcessGossipSection(clusterMsg *hdr, clusterLink *link) { |
nodeIp2String
转换ip到字符串
1 | void nodeIp2String(char *buf, clusterLink *link, char *announced_ip) { |
nodeUpdateAddressIfNeeded
更新节点地址,接收到其余节点的发送的gossip消息时,根据其消息里自己的地址和当前连接的地址来更新自己存储的信息,优先级为:消息 > 当前连接
1 | int nodeUpdateAddressIfNeeded(clusterNode *node, clusterLink *link, |
clusterSetNodeAsMaster
设置节点为master
1 | void clusterSetNodeAsMaster(clusterNode *n) { |
clusterUpdateSlotsConfigWith
更新槽点配置,节点交流时,会汇报自己管理的槽点,接收方需要根据此来更新自己的路由表
1 | void clusterUpdateSlotsConfigWith(clusterNode *sender, uint64_t senderConfigEpoch, unsigned char *slots) { |
clusterProcessPacket
处理数据包,读取集群节点发送的数据,解析消息执行。在该方法中,需要注意一点,link->node->name和hdr->sender。节点在发送消息时,会在消息里填上自己的name也就是hdr->sender。
1 | int clusterProcessPacket(clusterLink *link) { |
handleLinkIOError
处理连接IO错误
1 | void handleLinkIOError(clusterLink *link) { |
clusterWriteHandler
处理连接写操作,将缓冲区内容发送出去
1 | void clusterWriteHandler(aeEventLoop *el, int fd, void *privdata, int mask) { |
clusterReadHandler
处理连接读操作,在第一次建立完连接后,所有的消息处理都是在这里
1 | void clusterReadHandler(aeEventLoop *el, int fd, void *privdata, int mask) { |
clusterSendMessage
向连接发送消息
1 | void clusterSendMessage(clusterLink *link, unsigned char *msg, size_t msglen) { |
clusterBroadcastMessage
向所有有效节点发送消息
1 | void clusterBroadcastMessage(void *buf, size_t len) { |
clusterBuildMessageHdr
构建消息头
1 | void clusterBuildMessageHdr(clusterMsg *hdr, int type) { |
clusterNodeIsInGossipSection
判断某个节点是否在gossip协议中
1 | int clusterNodeIsInGossipSection(clusterMsg *hdr, int count, clusterNode *n) { |
clusterSetGossipEntry
设置goosip第一个消息
1 | void clusterSetGossipEntry(clusterMsg *hdr, int i, clusterNode *n) { |
clusterSendPing
发送心跳检测命令,根据type决定是ping/pong/meet,因为这三者只有类型不同,其余都一样
1 | void clusterSendPing(clusterLink *link, int type) { |
clusterBroadcastPong
向所有节点广播pong消息
1 |
|
clusterSendPublish
发布消息,link为空时,目标为所有节点
1 | void clusterSendPublish(clusterLink *link, robj *channel, robj *message) { |
clusterSendFail
广播某个节点客观下线
1 | void clusterSendFail(char *nodename) { |
clusterSendUpdate
告诉某个节点其配置需要更新
1 | void clusterSendUpdate(clusterLink *link, clusterNode *node) { |
clusterSendModule
发送模块消息,link为空时,目标为所有节点
1 | void clusterSendModule(clusterLink *link, uint64_t module_id, uint8_t type, |
clusterSendModuleMessageToTarget
向目标发送模块消息
1 | int clusterSendModuleMessageToTarget(const char *target, uint64_t module_id, uint8_t type, unsigned char *payload, uint32_t len) { |
clusterPropagatePublish
广播发布消息
1 | void clusterPropagatePublish(robj *channel, robj *message) { |
slave节点相关
clusterRequestFailoverAuth
向所有节点发起投票请求
1 | void clusterRequestFailoverAuth(void) { |
clusterSendFailoverAuth
回复投票确认,不投票的节点,是不发这个消息的
1 | void clusterSendFailoverAuth(clusterNode *node) { |
clusterSendMFStart
向某个节点发送手动修复消息
1 | void clusterSendMFStart(clusterNode *node) { |
clusterSendFailoverAuthIfNeeded
收到请求投票的请求,处理要不要为其投票
1 | void clusterSendFailoverAuthIfNeeded(clusterNode *node, clusterMsg *request) { |
clusterGetSlaveRank
当自己是salve时,其他slave中同步偏移量比自己大的数量
1 | int clusterGetSlaveRank(void) { |
clusterLogCantFailover
记录不能发起故障修复的原因日志
1 | void clusterLogCantFailover(int reason) { |
clusterFailoverReplaceYourMaster
从节点在选举成功后,用自己替换掉master
1 | void clusterFailoverReplaceYourMaster(void) { |
clusterHandleSlaveFailover
slave处理故障修复入口,包括发起、修正、重试
1 | void clusterHandleSlaveFailover(void) { |
slave迁移
clusterHandleSlaveMigration
把salve变成另一个master的salve,为了解决部分master下有多个状态良好的salve,一些master下一个状态良好的salve都没有的情况
1 | void clusterHandleSlaveMigration(int max_slaves) { |
手动修复
resetManualFailover
重置手动修复信息
1 | void resetManualFailover(void) { |
manualFailoverCheckTimeout
手动修复过程检查超时
1 | void manualFailoverCheckTimeout(void) { |
clusterHandleManualFailover
手动修复入口,用于处理能否向下一步走
1 | void clusterHandleManualFailover(void) { |
集群定时任务
clusterCron
和大部分的定时任务一样,都是由上一层的serverCron调用
1 | void clusterCron(void) { |
clusterBeforeSleep
事件循环前要做的事情
1 | void clusterBeforeSleep(void) { |
clusterDoBeforeSleep
设置事件循环前要做的事
1 | void clusterDoBeforeSleep(int flags) { |
槽点
bitmapTestBit
判断位图中某个槽点是否命中
1 | int bitmapTestBit(unsigned char *bitmap, int pos) { |
bitmapSetBit
设置位图中的某个槽点
1 | void bitmapSetBit(unsigned char *bitmap, int pos) { |
bitmapClearBit
清空位图的某个槽点
1 | void bitmapClearBit(unsigned char *bitmap, int pos) { |
clusterMastersHaveSlaves
判断所有的master是否至少一个有slave
1 | int clusterMastersHaveSlaves(void) { |
clusterNodeSetSlotBit
节点位图增加某个槽位
1 | int clusterNodeSetSlotBit(clusterNode *n, int slot) { |
clusterNodeClearSlotBit
清空节点位图中的某个槽位
1 | int clusterNodeClearSlotBit(clusterNode *n, int slot) { |
clusterNodeGetSlotBit
获取节点位图中是否包含某个槽位
1 | int clusterNodeGetSlotBit(clusterNode *n, int slot) { |
clusterAddSlot
节点增加槽位
1 | int clusterAddSlot(clusterNode *n, int slot) { |
clusterDelSlot
节点删除槽位
1 | int clusterDelSlot(int slot) { |
clusterDelNodeSlots
删除节点的所有槽位
1 | int clusterDelNodeSlots(clusterNode *node) { |
clusterCloseAllSlots
清空所有的迁入迁出槽点
1 | void clusterCloseAllSlots(void) { |
集群状态
clusterUpdateState
1 |
|
verifyClusterConfigWithData
验证集群配置
1 | int verifyClusterConfigWithData(void) { |
salve节点操作
clusterSetMaster
设置节点n为我们的master
1 | void clusterSetMaster(clusterNode *n) { |
节点到字符串的转换
redisNodeFlags
节点标志对应的描述说明
1 | struct redisNodeFlags { |
representClusterNodeFlags
把标志转换成对应的描述
1 | sds representClusterNodeFlags(sds ci, uint16_t flags) { |
clusterGenNodeDescription
获取节点的描述情况
1 | sds clusterGenNodeDescription(clusterNode *node) { |
clusterGenNodesDescription
排除掉包含某些标志节点,其他节点的描述
1 | sds clusterGenNodesDescription(int filter) { |
集群命令
clusterGetMessageTypeString
根据命令类型,获取命令文字描述
1 | const char *clusterGetMessageTypeString(int type) { |
getSlotOrReply
校验槽点是否合法
1 | int getSlotOrReply(client *c, robj *o) { |
clusterReplyMultiBulkSlots
输出所有槽点的情况,已节点为单位
1 | void clusterReplyMultiBulkSlots(client *c) { |
clusterCommand
响应cluster命令的入口
1 | void clusterCommand(client *c) { |
createDumpPayload
序列化redis对象,并存入rio
1 | void createDumpPayload(rio *payload, robj *o) { |
restoreCommand
恢复key value,使用序列化的数据,格式RESTORE key ttl serialized-value [REPLACE]
1 | void restoreCommand(client *c) { |
key迁移操作
redis提供了原子性的key迁移命令,维护了一个跟目标节点连接fd缓存区server.migrate_cached_sockets,防止在短时间内多次迁移需要建立多个连接
migrateGetSocket
获取跟host的连接,优先从缓存中取
1 |
|
migrateCloseSocket
关闭fd连接
1 | void migrateCloseSocket(robj *host, robj *port) { |
migrateCloseTimedoutSockets
关闭一段时间没有使用的fd
1 | void migrateCloseTimedoutSockets(void) { |
migrateCommand
原子性把一个key迁移到另一个节点,有两种格式
- 单个
MIGRATE host port key dbid timeout [COPY | REPLACE | AUTH password] - 批量
MIGRATE host port "" dbid timeout [COPY | REPLACE | AUTH password] KEYS key1 key2 keyN
1 | void migrateCommand(client *c) { |
askingCommand
响应ask命令
1 | void askingCommand(client *c) { |
readonlyCommand
响应客户端进入只读模式
1 | void readonlyCommand(client *c) { |
readwriteCommand
响应客户端进去写模式
1 | void readwriteCommand(client *c) { |
getNodeByQuery
查询能处理该命令的节点信息
1 | clusterNode *getNodeByQuery(client *c, struct redisCommand *cmd, robj **argv, int argc, int *hashslot, int *error_code) { |
clusterRedirectBlockedClientIfNeeded
对于阻塞的操作,检查存在问题,返回对应的错误
1 | int clusterRedirectBlockedClientIfNeeded(client *c) { |