redis-主从
为提升redis的性能,从实例的数量上来解决这个问题,可以使用redis的主从同步功能。可以在启动前预先配置拓扑结构,也可以在运行中动态改变拓扑结构。redis主从同步的命令主要有两个sync和psync。psync是sync的升级版本,具有断开续传的特点,解决了sync只能全量更新的问题。
同步场景
redis同步主要分为三种场景
- master和slave已经连接上:master会向slave发送一些列的命令流,当master有数据变更时,包括处理客户端的写入、过期和淘汰场景
- master和slave断开重连后:slave会尝试部分同步,获取从断开连接后的数据
- 无法进行部分同步:slave会请求全量更新,然后就会变成情况一
master和slave构成的拓扑结构,可以是多层的,即slave下也可以有多个slave,为了区分,称之为sub-slave。sub-slave收到的数据都是从最顶层的master传输下来的数据。
同步原理
每一个master有以下三个要素
- 身份标识replid: 这是40字节长度的随机字符串
- 同步数据缓冲区: 默认是1M的内存块,使用的时候作为环形使用。master会把要同步的数据做两步处理,一是发送给从节点,二是放到数据缓冲区,以便断开重连的slave能找到历史数据
- 偏移量: 标识自己产生了多少字节的同步数据,是缓冲区数据总的数据长度。客户端发起部分重传时,要求的偏移量必须比这个小
相关命令有slaveof和replicaof
slaveof/replicaof no one //停止同步,当前实例变成master
slaveof/replicaof hostname port //更改当前节点的master,如果节点已经是某个master的从节点,会舍弃当前的数据
slave本意为奴隶,是一个敏感词汇,让人联想到奴隶制相关的。redis作者迫于大量的批评压力,被迫新增一个别名
replica,用replicaof逐渐的替换slaveof。
数据结构
在redisServer结构体中,涉及到主从同步的属性如下所述
1 | struct redisServer { |
同步缓冲区的示意图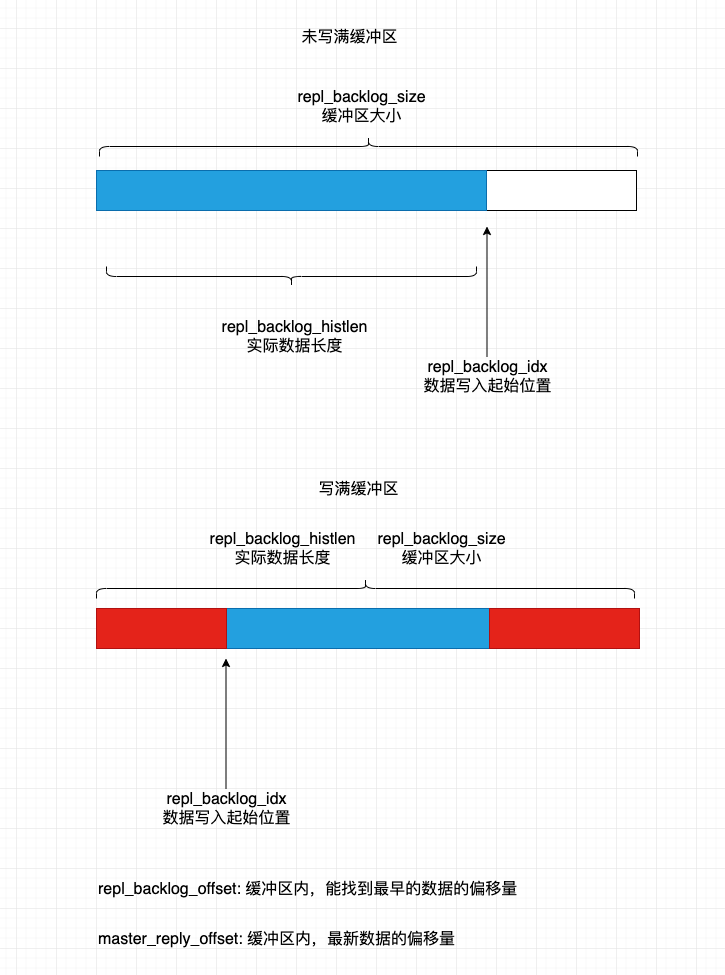
同步流程
master和slave的大部分交互都是在定时任务replicationCron中进行的,这个定时任务的上级是serverCron,频率是1秒1次。总体的流程如下:
- 一个即将成为slave的redis实例启动后,其状态为
REPL_STATE_NONE,表示不需要进行 - 接收
slaveof或replicaof命令后,更新master的ip和端口,状态变为REPL_STATE_CONNECT,表示等待连接(如果redis配置文件中配置了,启动的时候就到这一步了) - 发送
PING命令,状态变为REPL_STATE_RECEIVE_PONG,表示等待接收PONG回复 - 接收到
PONG返回,状态变为REPL_STATE_SEND_AUTH,表示接下来要发送密码。ping->pong这一来一回,是为了验证网络连接正常 - 发送验证密码,状态变为
REPL_STATE_RECEIVE_AUTH,表示等待接收回复确认。如果masterauth为空的话,跳过该阶段 - 收到OK回复,状态变成
REPL_STATE_SEND_PORT,表示加下来要发送同步数据用到的端口 - 发送
replconf listening-port xxxx,告知使用的端口,状态变成REPL_STATE_RECEIVE_PORT,表示等待接收回复确认 - 收到OK回复,状态变成
REPL_STATE_SEND_IP,表示接下来要发送同步数据用到的ip - 发送
replconf ip-address xxxx,告知同步使用的ip,状态变成REPL_STATE_RECEIVE_IP,表示等待接收回复确认 - 收到OK回复,状态变成
REPL_STATE_SEND_CAPA,表示接下来要发送支持功能 - 发送
replconf capa eof capa psync2,表明支持eof、psync2协议,状态变成REPL_STATE_RECEIVE_CAPA,表示等待接收回复确认 - 收到OK回复,状态变成
REPL_STATE_SEND_PSYNC,表示接下来要发送psync命令 - 发送psync命令,状态变成
REPL_STATE_RECEIVE_PSYNC,表示等待接收回复确认 - 收到psync回复,根据返回的结果不同,分为以下几种情况
- 返回
CONTINUE,用于断开又连上的场景 - 返回
FULLRESYNC,表示接下来要进行全量同步 - 返回不支持psync命令,然后发送sync
- 返回其余报错信息,服务端此刻没有能力响应,如加载db中或者master不是根节点,作为一个slave还没有连接上它自己的master
第一种情况,状态变为REPL_STATE_CONNECTED,表示已经连接上
第二种和第三种情况,状态会变为REPL_STATE_TRANSFER,表示等待接受master发送rdb数据
整个过程的失败和第四种情况一样,会关闭连接,状态变更到REPL_STATE_CONNECT,下一次replicationCron的时候又会重新发起上述流程
- 接收完master发送的rdb数据后,用来初始化db,状态变成
REPL_STATE_CONNECTED,表示已经连接上 - 接收master发送过来的增量数据,然后执行,稳定状态
除主流程之外,定时任务还做了以下几点事情:
- 超时检测,包括,连接超时、传输超时
- 心跳检测,发送
PING命令,收到PONG回复 - 发送ack信息,slave会向master发送ack信息,告知自己的同步的偏移量
- 清理同步数据缓冲区
- 统计状态良好的slave数量,可能影响到master对于写命令的响应
- 无盘模式下,为所有等待rdb文件的slave,创建能共用的rdb
源码分析
replicationGetSlaveName
获取从节点的名称ip:port,为空的话返回client的id,主要是在记log的时候用到
1 | char *replicationGetSlaveName(client *c) { |
createReplicationBacklog
创建同步数据缓冲区
1 | void createReplicationBacklog(void) { |
resizeReplicationBacklog
调整数据缓冲区的大小
1 | void resizeReplicationBacklog(long long newsize) { |
freeReplicationBacklog
释放数据缓冲区
1 | void freeReplicationBacklog(void) { |
feedReplicationBacklog
往数据缓冲区内写入数据,最底层的入口
1 | void feedReplicationBacklog(void *ptr, size_t len) { |
feedReplicationBacklogWithObject
往数据缓冲区内写入object类型
1 | void feedReplicationBacklogWithObject(robj *o) { |
replicationFeedSlaves
向从节点同步数据
1 | void replicationFeedSlaves(list *slaves, int dictid, robj **argv, int argc) { |
replicationFeedSlavesFromMasterStream
同步从master接收到的数据给自己的从节点,针对在拓扑结构中处于中间位置的节点
1 | void replicationFeedSlavesFromMasterStream(list *slaves, char *buf, size_t buflen) { |
replicationFeedMonitors
以监控者模式,发送同步信息
1 | void replicationFeedMonitors(client *c, list *monitors, int dictid, robj **argv, int argc) { |
addReplyReplicationBacklog
向客户端发送缓冲区内的数据,从offset开始,用于断开重传场景
1 | long long addReplyReplicationBacklog(client *c, long long offset) { |
getPsyncInitialOffset
获取当前节点的最大偏移量,回复客户端psync命令
1 | long long getPsyncInitialOffset(void) { |
replicationSetupSlaveForFullResync
给客户端回复需要全量同步,操作该方法之后,节点是处于等待rdb结束的状态
1 | int replicationSetupSlaveForFullResync(client *slave, long long offset) { |
masterTryPartialResynchronization
master尝试部分重传,返回C_ERR表示需要全量重传
1 | int masterTryPartialResynchronization(client *c) { |
startBgsaveForReplication
为了全量同步执行rdb操作
1 | int startBgsaveForReplication(int mincapa) { |
syncCommand
响应客户端的sync/psync命令
1 | void syncCommand(client *c) { |
replconfCommand
响应客户端replconf命令,在握手阶段传输ip/端口/能力信息、同步ack信息等
1 | void replconfCommand(client *c) { |
putSlaveOnline
把从节点设置成在线状态,重新挂客户端连接的写事件,因为sync的时候,已经禁止了客户端的输出
1 | void putSlaveOnline(client *slave) { |
sendBulkToSlave
发送rdb文件给从节点
1 | void sendBulkToSlave(aeEventLoop *el, int fd, void *privdata, int mask) { |
updateSlavesWaitingBgsave
rdb结束后的处理工作,1.发送内容给从节点 2.如果还有其他节点需要rdb文件,开始一个新的rdb流程
1 | void updateSlavesWaitingBgsave(int bgsaveerr, int type) { |
changeReplicationId
生成主repl id,用来标识来源
1 | void changeReplicationId(void) { |
clearReplicationId2
清除次repl id
1 | void clearReplicationId2(void) { |
shiftReplicationId
把主replid分给次replid
1 | void shiftReplicationId(void) { |
slaveIsInHandshakeState
判断从节点是否处于握手流程中
1 | int slaveIsInHandshakeState(void) { |
replicationSendNewlineToMaster
发送空行信息给master,防止超时,两种情况下用到1.清空db 2.使用rdb文件初始化db
1 | void replicationSendNewlineToMaster(void) { |
replicationEmptyDbCallback
清空数据库的回调,防止连接超时
1 | void replicationEmptyDbCallback(void *privdata) { |
replicationCreateMasterClient
创建master客户端,在成功建立连接后执行
1 | void replicationCreateMasterClient(int fd, int dbid) { |
restartAOF
重启aof,从节点在接收到rdb文件并且加载完后,需要根据之前的设置决定是否重启aof
1 | void restartAOF() { |
readSyncBulkPayload
从节点读取master发送过来的数据,分为rdb文件和无盘两种形式,rdb文件一开始就知道总的长度,无盘模式则是用特殊标记开始和结束,基于此读取的方式也不一样
1 |
|
sendSynchronousCommand
对master的fd进行读/写数据,在数据传输阶段之前都是使用该方法
1 |
|
slaveTryPartialResynchronization
客户端使用psync发起同步,发送请求/读取请求结果
发送的话,可能返回以下几种结果
PSYNC_WRITE_ERROR: 发送失败
PSYNC_WAIT_REPLY: 发送成功,下一次读就行了
读的话,可能返回以下几种结果
PSYNC_CONTINUE: master返回continue,表示可以断点续传
PSYNC_FULLRESYNC: master返回表示需要全量同步
PSYNC_NOT_SUPPORTED: master不支持psync命令
PSYNC_TRY_LATER: 还没有返回,过会再查
1 |
|
syncWithMaster
和master建立连接过程的处理,握手
1 | void syncWithMaster(aeEventLoop *el, int fd, void *privdata, int mask) { |
connectWithMaster
创建和master的socket连接
1 | int connectWithMaster(void) { |
undoConnectWithMaster
断开master的socket连接
1 | void undoConnectWithMaster(void) { |
replicationAbortSyncTransfer
中断和master传输,在传输过程中发现数据异常的情况
1 | void replicationAbortSyncTransfer(void) { |
cancelReplicationHandshake
取消和mater的握手过程,分为连接阶段和传输阶段
1 | int cancelReplicationHandshake(void) { |
replicationSetMaster
设置master的ip和端口
1 | void replicationSetMaster(char *ip, int port) { |
replicationUnsetMaster
取消同步,把自己变成一个master
1 | void replicationUnsetMaster(void) { |
replicationHandleMasterDisconnection
和master断开连接后的处理
1 | void replicationHandleMasterDisconnection(void) { |
replicaofCommand
响应replicaf、slaveof命令
1 | void replicaofCommand(client *c) { |
roleCommand
响应role命令,获取角色信息master/salve,以及附带信息
1 | void roleCommand(client *c) { |
replicationSendAck
发送ack命令,告知master自己的同步offset
1 | void replicationSendAck(void) { |
replicationCacheMaster
缓存master client,用于和master断开连接后,因为后续重连的话可以直接继续用的
1 | void replicationCacheMaster(client *c) { |
replicationCacheMasterUsingMyself
当前实例自己充当cache_master
1 | void replicationCacheMasterUsingMyself(void) { |
replicationDiscardCachedMaster
舍弃cache_master
1 | void replicationDiscardCachedMaster(void) { |
replicationResurrectCachedMaster
把cache_master转为master,并更新fd,用于断开重连之后
1 | void replicationResurrectCachedMaster(int newfd) { |
refreshGoodSlavesCount
统计良好状态的从节点数量
1 | void refreshGoodSlavesCount(void) { |
replicationScriptCacheInit
同步脚本缓存初始化
1 | void replicationScriptCacheInit(void) { |
replicationScriptCacheFlush
清空脚本
1 | void replicationScriptCacheFlush(void) { |
replicationScriptCacheAdd
增加缓存脚本
1 | void replicationScriptCacheAdd(sds sha1) { |
replicationScriptCacheExists
判断脚本是否存在
1 | int replicationScriptCacheExists(sds sha1) { |
replicationRequestAckFromSlaves
设置从从节点获取ack信息,下一次beforeSleep的时候 会向从节点发送reploconf getack 命令
1 | void replicationRequestAckFromSlaves(void) { |
replicationCountAcksByOffset
统计ack大于某一个阈值的从节点数量
1 | int replicationCountAcksByOffset(long long offset) { |
waitCommand
响应watch命令
1 | void waitCommand(client *c) { |
unblockClientWaitingReplicas
不阻塞客户端
1 | void unblockClientWaitingReplicas(client *c) { |
processClientsWaitingReplicas
1 | void processClientsWaitingReplicas(void) { |
replicationGetSlaveOffset
获取master的offset
1 | long long replicationGetSlaveOffset(void) { |
replicationCron
主从同步的定时任务
1 | void replicationCron(void) { |