redis-rdb
rdb作为redis的另一种数据持久化方式,其用途有两种。1、数据持久化,把数据存放到磁盘上。2、主从数据同步,当第一次同步或者从节点同步的信息不在主节点的缓冲区内时,会生成一个rdb文件,然后同步给从节点用于生成初始数据集。
开启条件
rdb的开启,分为主动和被动两种。
主动
redis 有一个配置项save seconds changes,表示数据库在seconds后,有changes个key改变了。redis默认有三个配置:1小时改变1次、5分钟改变100次、1分钟改变10000次,此配置可以在redis的配置文件中更改,也可以在运行期间使用config save seconds changes进行修改,config save “” 表示把配置项内容清空。在serverCron中,会去计算距离上一次数据保存过了多久以及数据库有多少个key改变了。然后和save的配置项依次比较,如果满足时间大于等于seconds、改变次数大于等于changes、上一次rdb成功或时间大于失败重试时间(默认5秒),则进行rdb数据备份。
被动
开启rdb也可以通过客户端发送命令save、bgsave来手动开启,save没有创建子进程,而是在主进程进行rdb备份,因此会阻塞其他客户端的请求一直到rdb备份完成,所以需要慎用。bgsave则是正常的创建一个子进程,子进程去负责rdb数据备份。该命令有一个schedule参数,有无该参数影响点是在命令执行时,当有aof或者rdb正在进行的情况。没有该参数的话,会返回错误表明已经有一个子进程在备份数据了;有该参数的话,则会在下一次serverCron时判断是否曼满足没有aof在进行、没有rdb在进行、上一次rdb成功或时间大于失败重试时间(默认5秒),满足的话进行rdb数据备份。
还有一种情况是在主从数据同步的时候,在一开始亦或者从节点要求同步的数据在主节点的同步数据缓存中找不到,主节点会执行rdb备份,把该文件发送给从节点用于构建数据集。
RDB流程
主动的数据备份过程可以分为以下几步
- 父进程fock子进程
- 父进程记录开始时间、子进程id
- 子进程关闭sockets监听
- 子进程创建临时文件并进行db数据备份
- 重命名临时文件为正式文件
文件格式
rdb为了让最后生成的文件尽可能的小,rdb定义了一系列的操作和数据格式,对于常用的几类数据类型,存储方式如下:
浮点型:浮点型数据有两种存储形式,一种是转换成字符串写入,一种按照二进制存储
字符串:分为压缩和不压缩两种,通用形式都是先存储字符串长度,然后存储内容
整形:采用特殊编码规则,根据一个字节的前两位,代表的含义如下
00|XXXXXX 剩余的6位表示数据长度
01|XXXXXX XXXXXXXX 剩余的6位+下个字节的8位共14位表示数据长度
10|000000 下个字节开始的32位表示数据长度
10|000001 下个字节开始的64位表示数据长度大小
11|XXXXXX 特殊编码,具体是那种编码,取决于剩余6位的值,根据值不同分为以下几种:
0:8位整形
1:16位整形
2:32位整形
3:压缩的字符串
文件构成
- 以REDIS+4位RDB_VERSION开始,然后依次写入
- 辅助信息,包括
redis-ver、redis-bits、ctime、used-mem、aof-preamble字段,如果是在主从同步的场景的话,会额外包含repl-stream-db、repl-id、repl-offset字段。 选择DB操作- DB索引
- 设置DB大小操作
- DB存储hash大小
- DB过期hash大小
- 遍历该DB下所有存储节点,依次写入
- 过期时间操作&过期时间(如果设置过期)
- lru操作&信息(如果redis达到最大内存时的淘汰策略为lru)
- lfu操作&信息(如果redis达到最大内存时的淘汰策略为lfu)
- value对象类型
- Key对象(都是string)
- value对象
- lua脚本信息
- 结束操作
- 8个字节的数据校验
示例解析
接下来,以一个简单的rdb文件为例,执行rdb时,redis只有一个(key,value)为(a,100)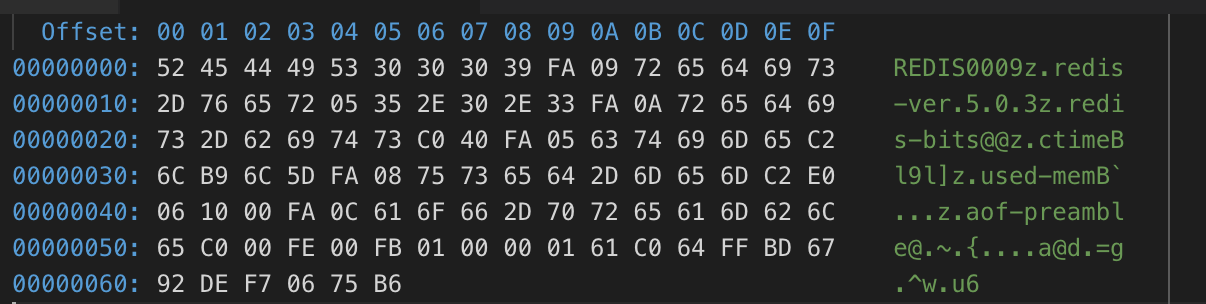
- 前9个字节,是正常的REDIS+RDB_VERSION,通过后4位可以看出RDB_VERSION版本是9
- 第10个字节是
FA,表示写入辅助信息 - 第11个字节是
09,表示接下来是9个字节的字符串,为辅助信息的key - 第12-20个字节是
redis-ver,确定key - 第21个字节是
05,表示接下来是5个字节的字符串,为辅助信息的value - 第22-26个字节是
5.0.3,确定value - 第27个字节是
FA,表示写入辅助信息 - 第28个字节是
0A,表示接下来是10个字节的字符串,为辅助信息的value - 第29-38个字节是
redis-bits,确定key - 第39个字节是
C0,二进制表示为11000000,11表示为特殊编码类型,后四位0000表示8位无符号整形,综合起来,下一个字节是无符号整形 - 第40个字节是
40,10进制表示为64,确定value,结合key意思为redis-bits是64位 - 后面一直到第83个字节,都是如此,依次表示辅助信息
ctime、used-mem,aof-preamble - 第68字节是
FE,表示选择DB操作 - 第69字节是
00,表示DB索引是0 - 第70个字节是
FB,表示设置DB大小操作 - 第71、72字节是
01和00,分别表示DB存储hash大小为1和过期hash大小为0 - 第73个字节是
00表示value类型是string - 第74个字节是
01,表示key的长度 - 第75个字节是
61,确定key的值为a - 第76个字节是
C0,表示8位无符号整形特殊编码 - 第77个字节是
64,确定值为100 - 第78个字节是
FF,表示RDB结束 - 最后79-86共8个字节,是数据校验的结果
源码分析
rdbWriteRaw
往rdb中写入原生数据,各种类型的写入都是先进行转换,最后调用该方法
1 | static int rdbWriteRaw(rio *rdb, void *p, size_t len) { |
rdbLoadRaw
从rdb中读取原生数据
1 | void rdbLoadRaw(rio *rdb, void *buf, uint64_t len) { |
rdbSaveType
保存RDB定义的操作类型
1 | int rdbSaveType(rio *rdb, unsigned char type) { |
rdbLoadType
读取RDB操作类型
1 | int rdbLoadType(rio *rdb) { |
rdbLoadTime
读取时间,适用于老版本使用RDB_OPCODE_EXPIRETIME标识过期时间,因此只有读方法,不再提供写方法
1 | time_t rdbLoadTime(rio *rdb) { |
rdbSaveMillisecondTime
保存毫秒时间
1 | int rdbSaveMillisecondTime(rio *rdb, long long t) { |
rdbLoadMillisecondTime
读取毫秒时间
1 | long long rdbLoadMillisecondTime(rio *rdb, int rdbver) { |
rdbSaveLen
保存长度值
1 | int rdbSaveLen(rio *rdb, uint64_t len) { |
rdbLoadLenByRef
读取数据长度,isencoded存储是否是额外编码,lenptr表示数据长度或者额外编码的类型
1 | int rdbLoadLenByRef(rio *rdb, int *isencoded, uint64_t *lenptr) { |
rdbLoadLen
读取数据长度
1 | uint64_t rdbLoadLen(rio *rdb, int *isencoded) { |
rdbEncodeInteger
对整形数字进行编码处理,根据值大小,结果存储在enc中
1 | int rdbEncodeInteger(long long value, unsigned char *enc) { |
rdbLoadIntegerObject
从rdb文件中读取一个整形对象,enctype表示按照哪种编码读,根据flag的标志位决定返回类型,具体返回情况参照rdbGenericLoadStringObject说明
1 | void *rdbLoadIntegerObject(rio *rdb, int enctype, int flags, size_t *lenptr) { |
rdbTryIntegerEncoding
尝试将字符串转换成integer类型
1 | int rdbTryIntegerEncoding(char *s, size_t len, unsigned char *enc) { |
rdbSaveLzfBlob
保存lzf压缩过的数据
1 | ssize_t rdbSaveLzfBlob(rio *rdb, void *data, size_t compress_len, |
rdbSaveLzfStringObject
保存lzf字符串对象,要求字符串长度不低于5,否则没有压缩的必要
1 | ssize_t rdbSaveLzfStringObject(rio *rdb, unsigned char *s, size_t len) { |
rdbLoadLzfStringObject
从rdb文件中读取lzf字符串对象,返回对象类型取决于flags标志位,参照rdbGenericLoadStringObject说明。此方法是建立在已经确认当前数据是lzf编码的基础上
1 | void *rdbLoadLzfStringObject(rio *rdb, int flags, size_t *lenptr) { |
rdbSaveRawString
保存字符串内容,会先尝试把字符串转换成整形以节省空间
1 | ssize_t rdbSaveRawString(rio *rdb, unsigned char *s, size_t len) { |
rdbSaveLongLongAsStringObject
保存长整形数据,会先尝试能否按照整形存储,否则转换成字符串存储
1 | ssize_t rdbSaveLongLongAsStringObject(rio *rdb, long long value) { |
rdbSaveStringObject
保存redis字符串对象,根据字符串编码类型不同,处理也有所不同。如果是数值型编码,按照整形,转换成字符串原始数据的顺序尝试存储,其余类型则按照整形,压缩,原始数据的顺序存储,二者之间的差距就是数值型编码不会尝试压缩处理。
1 | ssize_t rdbSaveStringObject(rio *rdb, robj *obj) { |
rdbGenericLoadStringObject
从rdb文件中读取字符串对象,flags决定了返回的对象类型,flags可以是一下几种的结合:
RDB_LOAD_NONE: 返回一个rdb对象,不用任何编码
RDB_LOAD_ENC: 如果返回是一个redis对象,尝试特殊对其进行特殊编码
RDB_LOAD_PLAIN: 返回一个字符串是zmalloc创建的而非redis对象
RDB_LOAD_SDS: 返回一个SDS字符串而非redis对象
1 | void *rdbGenericLoadStringObject(rio *rdb, int flags, size_t *lenptr) { |
rdbLoadStringObject
从rdb文件中读取string对象,不采用任何编码
1 | robj *rdbLoadStringObject(rio *rdb) { |
rdbLoadEncodedStringObject
从rdb中读取string对象,尝试采用embstr编码
1 | robj *rdbLoadEncodedStringObject(rio *rdb) { |
rdbSaveDoubleValue
往rdb中保存double类型数据,转换成字符串存储,其首个字节表示类型,如下:
253: 不是一个数字 NAN 0.0/0.0
254: 正无穷大 +INF 1.0/0.0
255: 负无穷大 -INF -1.0/0.0
1 | int rdbSaveDoubleValue(rio *rdb, double val) { |
rdbLoadDoubleValue
从rdb读取double类型
1 | int rdbLoadDoubleValue(rio *rdb, double *val) { |
rdbSaveBinaryDoubleValue
保存二进制格式的double数据
1 | int rdbSaveBinaryDoubleValue(rio *rdb, double val) { |
rdbLoadBinaryDoubleValue
从rdb读取二进制格式double类型
1 | int rdbLoadBinaryDoubleValue(rio *rdb, double *val) { |
rdbSaveBinaryFloatValue
保存二进制格式的float数据
1 | int rdbSaveBinaryFloatValue(rio *rdb, float val) { |
rdbLoadBinaryFloatValue
从rdb读取二进制格式float类型
1 | int rdbLoadBinaryFloatValue(rio *rdb, float *val) { |
rdbSaveObjectType
保存redis对象类型,从redis对象类型映射到rdb对象类型
1 | int rdbSaveObjectType(rio *rdb, robj *o) { |
rdbLoadObjectType
从rdb中读取对象类型
1 | int rdbLoadObjectType(rio *rdb) { |
rdbSaveStreamPEL
序列化消费者待处理列表,并写入rdb文件
1 | ssize_t rdbSaveStreamPEL(rio *rdb, rax *pel, int nacks) { |
rdbSaveStreamConsumers
序列化流式消费者,并保存到rdb中
1 | size_t rdbSaveStreamConsumers(rio *rdb, streamCG *cg) { |
rdbSaveObject
保存redis对象内容,分为string,list,set,zset,hash,stream,module类型
1 | ssize_t rdbSaveObject(rio *rdb, robj *o) { |
rdbSavedObjectLen
获取redis对象如果写入文件时,所需要的长度,为了懒省事就用rdbSaveObject方法,rio参数传了NULL,这样只返回长度,实际上是没有写入到文件的
1 | size_t rdbSavedObjectLen(robj *o) { |
rdbSaveKeyValuePair
写入一对key、value数据到rdb中,
1 | int rdbSaveKeyValuePair(rio *rdb, robj *key, robj *val, long long expiretime) { |
rdbSaveAuxField
写入一组辅助信息到rdb中
1 | ssize_t rdbSaveAuxField(rio *rdb, void *key, size_t keylen, void *val, size_t vallen) { |
rdbSaveAuxFieldStrStr
写入一对辅助信息到rdb文件,此方法应用于key,value可以用strlen确定长度的场景,否则用rdbSaveAuxField
1 | ssize_t rdbSaveAuxFieldStrStr(rio *rdb, char *key, char *val) { |
rdbSaveAuxFieldStrInt
写入一对辅助信息到rdb文件,如果辅助信息的value是long long类型,最终还是转换成string存储
1 | ssize_t rdbSaveAuxFieldStrInt(rio *rdb, char *key, long long val) { |
rdbSaveInfoAuxFields
写入所有辅助信息到rdb文件中,写入辅助信息的入口,写入的信息包括redis-ver,redis-bits,ctime,used-mem,repl-stream-db,repl-id,repl-offset,aof-preamble
1 | int rdbSaveInfoAuxFields(rio *rdb, int flags, rdbSaveInfo *rsi) { |
rdbSaveRio
rdb真正干事情的入口
1 | int rdbSaveRio(rio *rdb, int *error, int flags, rdbSaveInfo *rsi) { |
rdbSaveRioWithEOFMark
在正常的rdb内容前后加入一个前缀和后缀,前缀是$EOF:<40 bytes unguessable hex string>\r\n,后缀是<40 bytes unguessable hex string>,后缀是用来标识结束位置。这个方法主要是用在主从同步的场景。
1 | int rdbSaveRioWithEOFMark(rio *rdb, int *error, rdbSaveInfo *rsi) { |
rdbSave
往文件中写入rdb内容
1 | int rdbSave(char *filename, rdbSaveInfo *rsi) { |
rdbSaveBackground
创建子进程进行rdb
1 | int rdbSaveBackground(char *filename, rdbSaveInfo *rsi) { |
rdbRemoveTempFile
删除子进程生成的临时文件
1 | void rdbRemoveTempFile(pid_t childpid) { |
rdbLoadCheckModuleValue
读取check module数据
1 | robj *rdbLoadCheckModuleValue(rio *rdb, char *modulename) { |
rdbLoadObject
从特殊文件读取redis对象
1 | robj *rdbLoadObject(int rdbtype, rio *rdb) { |
startLoading
开始加载,设置全局变量
1 | void startLoading(FILE *fp) { |
loadingProgress
更新加载进度
1 | void loadingProgress(off_t pos) { |
stopLoading
停止加载,设置全局变量
1 | void stopLoading(void) { |
rdbLoadProgressCallback
rdb加载回调
1 | void rdbLoadProgressCallback(rio *r, const void *buf, size_t len) { |
rdbLoadRio
真正加载rdb文件的入口
1 | int rdbLoadRio(rio *rdb, rdbSaveInfo *rsi, int loading_aof) { |
rdbLoad
从指定文件中加载rdb
1 | int rdbLoad(char *filename, rdbSaveInfo *rsi) { |
backgroundSaveDoneHandlerDisk
以子进程执行rdb持久化时,子进程结束后,处理后续工作
1 | void backgroundSaveDoneHandlerDisk(int exitcode, int bysignal) { |
backgroundSaveDoneHandlerSocket
以子进程执行rdb,为了主从同步,子进程结束后,处理后续工作
1 | void backgroundSaveDoneHandlerSocket(int exitcode, int bysignal) { |
backgroundSaveDoneHandler
以子进程执行rdb,进程结束后,处理后续工作总的入口,分为两类持久化到磁盘&主从同步
1 | void backgroundSaveDoneHandler(int exitcode, int bysignal) { |
rdbSaveToSlavesSockets
生成rdb文件,把该文件同步给从节点
1 | int rdbSaveToSlavesSockets(rdbSaveInfo *rsi) { |
saveCommand
客户端执行save命令,同步执行rdb
1 | void saveCommand(client *c) { |
bgsaveCommand
客户端执行bgsave命令,分两种情况,一种是现在立即执行,一种是计划任务(如果现在不能执行的话,在后面serverCron中执行,如果满足条件的话)
1 | void bgsaveCommand(client *c) { |
rdbPopulateSaveInfo
填充rdbSaveInfo结构体,结构体的信息影响到rdb的动作,主要是主从同步的附带信息
1 | rdbSaveInfo *rdbPopulateSaveInfo(rdbSaveInfo *rsi) { |